Government Of India
A-
A
A+
Latest insights & developments from the world of Artificial Intelligence(AI).
AIkosha
Dataset
LLM Training
Dataset Distillation: Techniques, Advances, and Strategic Relevance for AIKosh
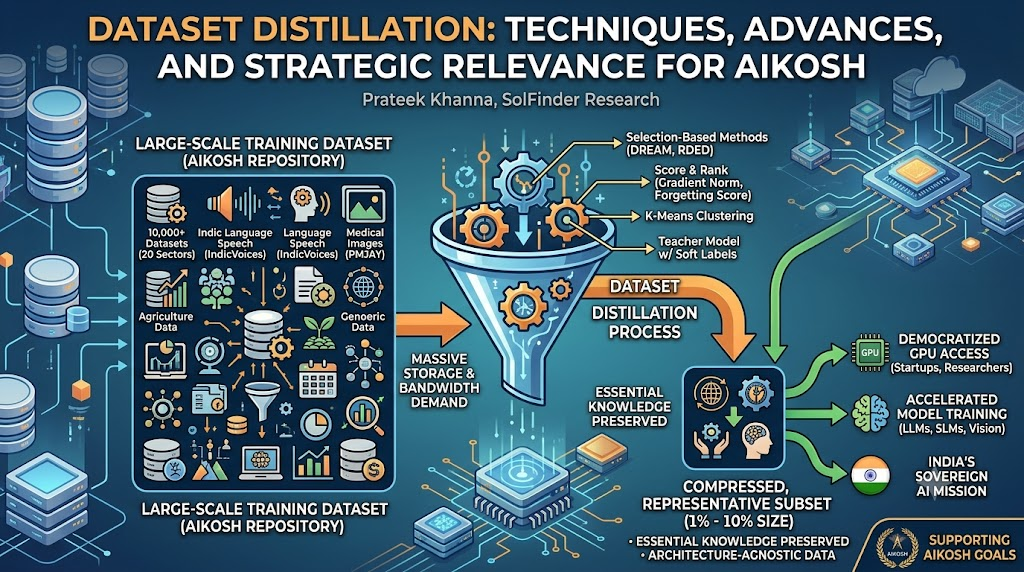
Dataset distillation is an emerging technique that compresses large-scale training datasets into small, informative synthetic or selected subsets while preserving the essential knowledge required for training high-performing machine learning models. This paper analyses the techniques in dataset distillation, with a particular focus on selection-based methods, and examines how these techniques can address AIKosh’s core challenges related to efficient storage, reduced computational costs, cross-architecture generalization, and democratized access to high-quality training data. The research proposes that integrating dataset distillation into AIKosh’s ecosystem can help accelerate India’s sovereign AI mission by enabling resource-constrained researchers and startups to train competitive models on compressed, representative data.
 0
0  28
28  2 min read
2 min read


Language
Language Access
Language Documentation
Northeast India
Northeast India Languages
Tribal Language Model
Building Sovereign Language AI for Northeast India: The NE-Stack Story
Northeast India is home to over 220 languages spoken by 45 million people, yet remains mostly absent from modern AI systems. MWire Labs, a northeast India AI startup based in Shillong, Meghalaya, is building the NE-Stack, a foundational suite of northeast AI models covering speech recognition, machine translation, OCR, TTS, and vision-language understanding across 11+ indigenous languages. This article documents the technical and strategic approach behind northeast AI development for one of the world's most linguistically diverse and digitally underserved regions.

- 0
- 7
- 1 min read
AI For All
AI for Social Good
Artificial Intelligence
Bharat
Content Creation
Ethical AI
MeitY
Synthetic Data
vikasit-ai
When India Spoke of Digital Authenticity: A Digital Nutrition Label for Provenance
At India AI Impact Summit 2026, digital authenticity emerged as a public responsibility connected to synthetic media, platform accountability, and citizen trust. Prime Minister Narendra Modi’s call for authenticity labels placed the issue in language ordinary people can understand: citizens need readable trust, not only raw manifests or expert tools.
The same summit also placed C2PA and Content Credentials inside the standards conversation, with leaders from Adobe, Google, MeitY, and the wider technology ecosystem discussing provenance, synthetic media, and accountability. C2PA Content Credentials provide the open standards foundation for making provenance inspectable across the global content ecosystem.
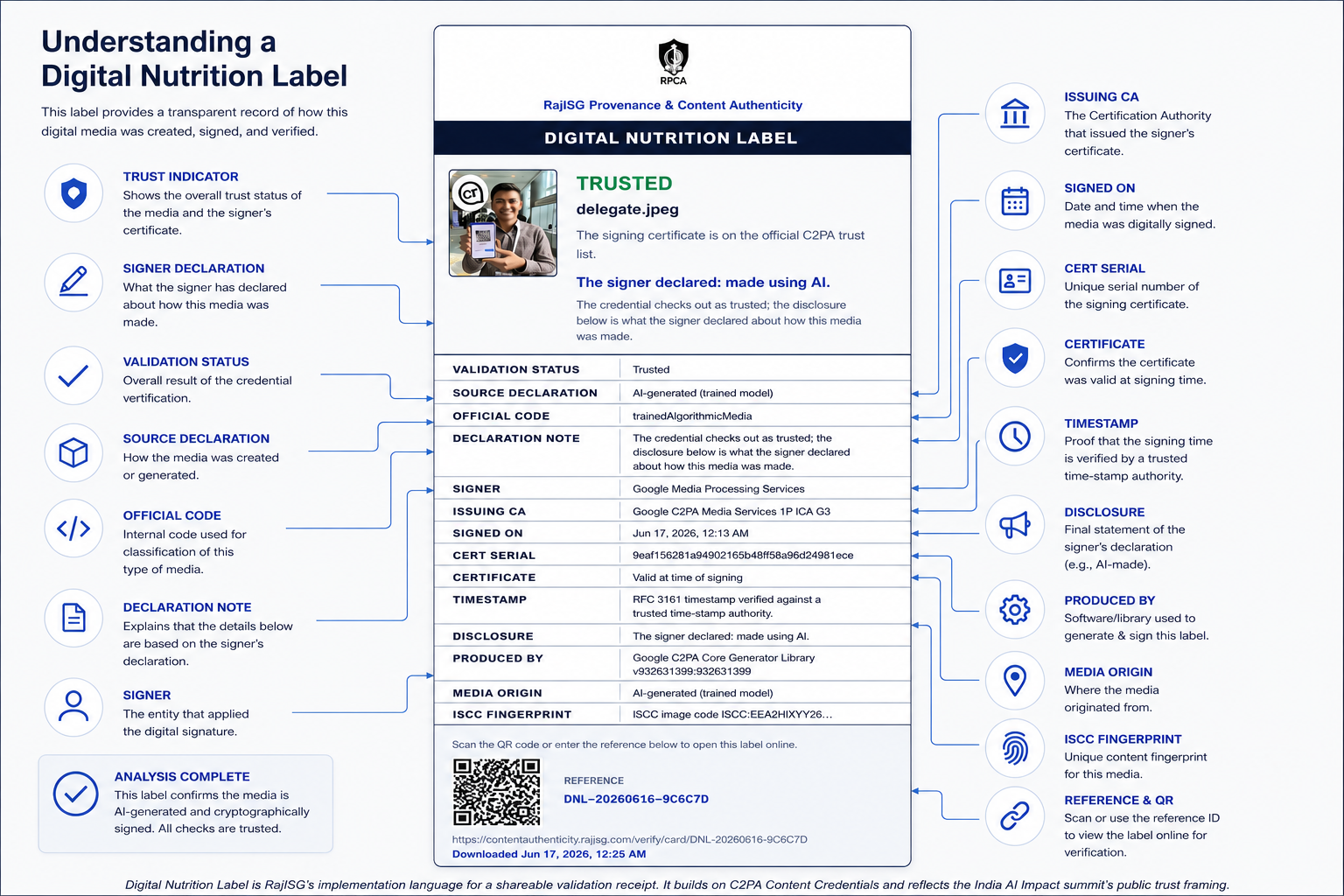
This Experts Speak article reflects on the next implementation challenge: how verified provenance becomes readable and useful after inspection. From RajISG’s perspective, it examines how a live Digital Nutrition Label implementation on RPCA can translate validated Content Credentials into a citizen readable receipt with verdict, disclosure rows, QR code, reference number, and frozen snapshot reopening on the live site.
The article argues that global responsibility in digital trust requires both open standards and implementation layers that help citizens, creators, institutions, and platforms actually use provenance in public life.
- 0
- 28
- 1 min read
Digital Twins
Foundation Models
sovereign-ai
From Foundation Models to World Models: Charting the Next Frontier of India's AI Ecosystem
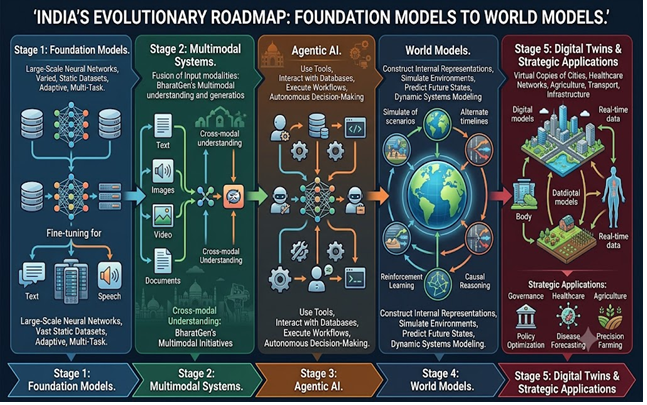
The emergence of foundation models has transformed artificial intelligence (AI) into a foundational digital infrastructure capable of supporting a wide range of applications involving language processing, computer vision, speech recognition, and multimodal interaction. India's sovereign AI initiatives, including the IndiaAI Mission, BharatGen, AIKosh, and the PARAM family of models, have established important building blocks for indigenous AI development. We are now poised for exploring beyond foundation models toward world models - AI systems capable of constructing internal representations of environments, simulating future states, reasoning about consequences, and supporting autonomous decision-making. This paper examines the transition from foundation models to world models and analyzes its implications for India's AI ecosystem. It argues that world models represent the logical next stage in the evolution of sovereign AI infrastructure and could enable transformative applications in governance, healthcare, agriculture, urban planning, scientific discovery, and digital public infrastructure. The paper further proposes a strategic roadmap through which IndiaAI can evolve from a model-centric ecosystem toward a simulation-driven AI ecosystem supported by digital twins, agentic systems, and domain-specific world models. Such a transition has the potential to position India at the forefront of next-generation artificial intelligence while strengthening technological sovereignty and national innovation capacity.
- 1
- 34
- 2 min read
AIkosha
Foundation Models
sovereign-ai
Managing Model Proliferation in Sovereign AI Ecosystems: Lessons from global AI Repositories for Indian context
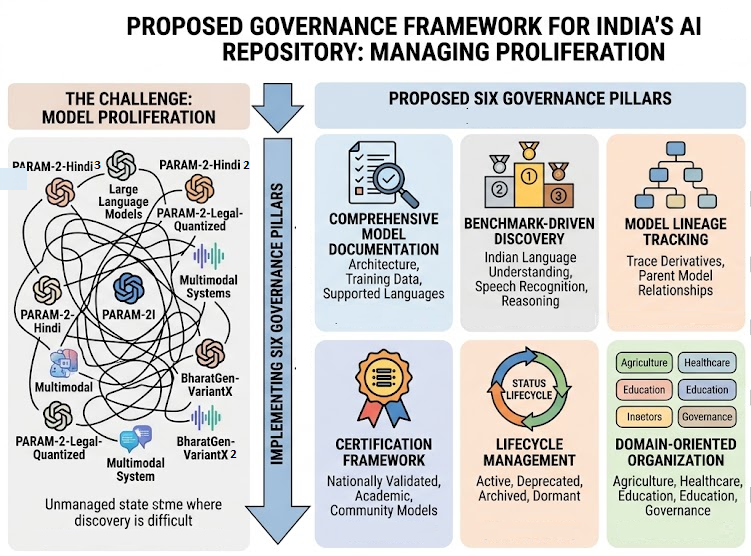
The rapid growth of foundation models tends to transform artificial intelligence (AI) repositories from simple storage platforms into complex ecosystems supporting model development, distribution, benchmarking, and deployment. As sovereign AI initiatives gain momentum worldwide, national repositories such as AIKosh under India's IndiaAI Mission are expected to host a rapidly expanding collection of datasets, foundation models, fine-tuned variants, adapters, benchmarks, and domain-specific AI systems. While this expansion can accelerate innovation, it also introduces the challenge of model proliferation, where the increasing number of available models complicates discovery, evaluation, governance, trust, and lifecycle management. This paper examines the emerging challenge of model proliferation in sovereign AI ecosystems and analyzes how lessons from global AI model repositories can inform the governance evolution in Indian context. The paper identifies potential areas of improvement in terms of governance framework, model discovery, lineage tracking, certification mechanisms, lifecycle management, and domain-oriented organization. The study argues that proactive governance will be essential to ensure that Indian AI model repositories remains transparent, trustworthy, discoverable, and aligned with India's sovereign AI objectives.
- 0
- 12
- 2 min read
IndicSynth
LLM
SyntheticData
IndicSynth: Building Synthetic Data for India's AI
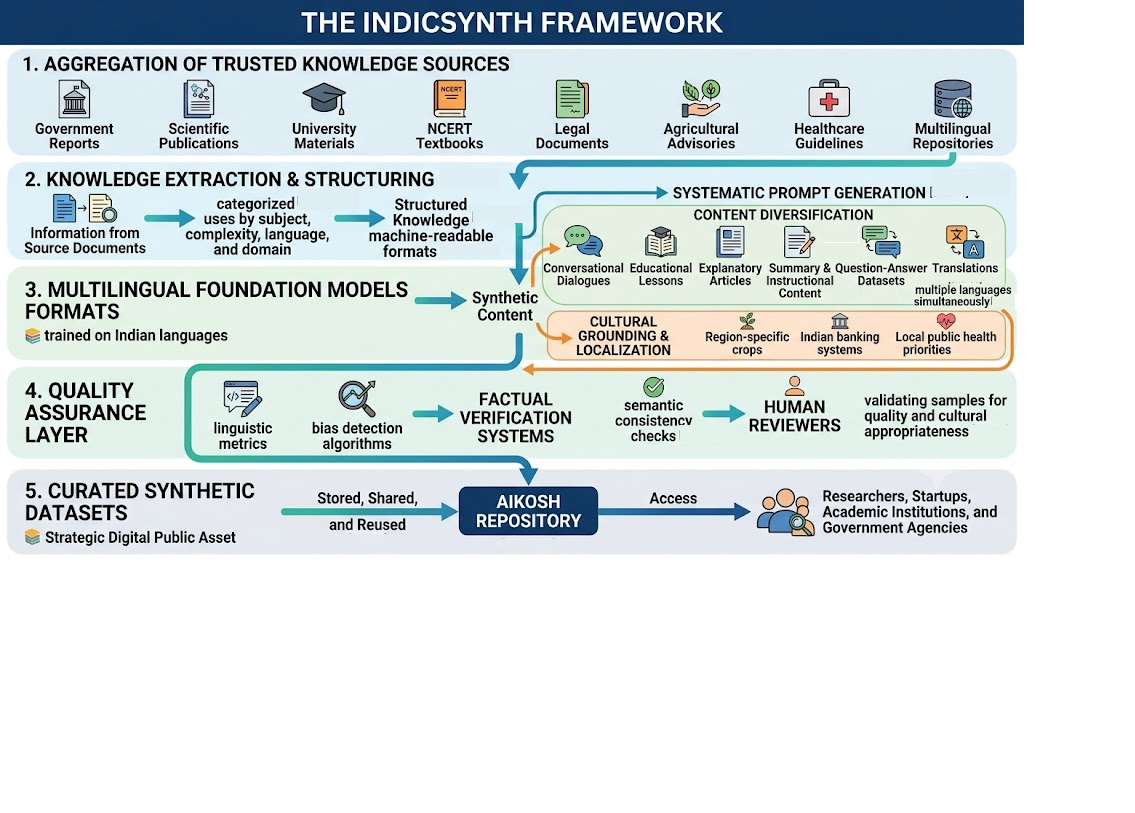
The emergence of Large Language Models (LLMs) has transformed the global artificial intelligence landscape by enabling machines to understand, generate, and reason over human language with unprecedented capabilities. However, the development of high-performing LLMs depends heavily on the availability of large volumes of high-quality training data. While English and a few other major global languages benefit from extensive digital corpora, many Indian languages remain significantly underrepresented in existing datasets. This disparity poses a major challenge for the development of inclusive and linguistically diverse AI systems capable of serving India's multilingual population. Synthetic data generation has recently emerged as a promising approach to address data scarcity while reducing dependence on costly and time-consuming human annotation. This article proposes IndicSynth, a conceptual framework for generating large-scale synthetic datasets tailored for Indian languages and domains. The framework envisions the integration of public knowledge repositories, domain-specific resources, multilingual foundation models, and quality assurance mechanisms to create culturally grounded and linguistically rich training corpora. The synthetic data can become a strategic digital public asset and the synthetic dataset generation framework can potentially be integrated within AIKosh to accelerate the development of sovereign Indian LLMs.
- 0
- 23
- 2 min read
AI evaluation
AI/ML Development
DPDP
multi-agent
responsible AI
From Gateway to Control Plane: Governing Agentic AI in India's Regulated Sectors
Our first article argued that India's enterprise AI governance challenge begins at the gateway — redacting Indian PII before data reaches a model. Agentic AI moves the harder problem one layer out: AI agents no longer just read data, they take actions — they file, transfer, query, and escalate across enterprise systems. The governance surface shifts from what a model sees to what an agent is allowed to do, and whether you can prove it afterwards.
This follow-up examines why the Model Context Protocol (MCP) — now stewarded by the Linux Foundation's Agentic AI Foundation and adopted across every major AI platform — is becoming the de facto control plane for enterprise AI, and why governing that control plane is structurally different for regulated India. We map the agentic risk surface (tool over-exposure, prompt injection, tool poisoning, schema drift) onto three Indian realities: the Data Fiduciary's continuing liability for autonomous agent actions under the DPDP Rules 2025, RBI's FREE-AI sutras of Accountability and Understandable-by-Design, and the sovereignty question of whether a regulated institution's AI nervous system should run on foreign SaaS.
We then specify what a sovereign, audit-ready agentic control plane must do — self-deployable, redact-before-tool-call, least-privilege per tool, deterministic policy enforcement, and immutable audit artefacts mapped to Indian regulation — and close with five recommendations for MeitY, RBI, and the IndiaAI Mission. With DPDP hard enforcement arriving in May 2027, the window to build India's own control plane is now.

- 0
- 9
- 1 min read
Agriculture Statistics
AI in Agriculture
Digital Transformation
Multilingual AI
Public Sector AI
Responsible AI
AI-Powered Multilingual Advisory Platform for Smallholder Farmers: Lessons from a Public Sector Digital Transformation Project in India
This solution write-up documents the design, development, and deployment of a multilingual AI-powered advisory platform that delivers personalized crop recommendations, pest alerts, weather insights, and government scheme information to smallholder farmers. Implemented as part of a district-level digital transformation initiative, the system bridges the information gap for farmers in regional languages, demonstrating measurable improvements in decision-making, yield awareness, and scheme uptake while upholding responsible AI principles

- 0
- 22
- 1 min read
AI For All
Ethical AI
global
MeitY
Policy and Governance
Responsible AI
Synthetic Data
vikasit-ai
Public Trust Infrastructure for India’s AI Era: Why Provenance Must Sit Beside Compute, Data, and Models
India’s AI ecosystem is advancing through compute, datasets, models, skilling, and applications. This article argues that provenance and content authenticity should sit beside those priorities as public trust infrastructure, helping citizens and institutions understand what was created, edited, shared, and verified in the AI era.

- 0
- 70
- 1 min read
agentic
indian-ai
AI Agent Architecture: The Trust Boundary Model
The blog introduces the Agent Trust Boundary Model, a framework for safely architecting AI agents around four core boundaries: what the agent can follow (instructions), read (data), call (tools), and change (actions), plus supporting boundaries for memory, state, identity, and observability. Its central principle is that untrusted content (emails, webpages, tickets, tool outputs) may inform the agent but must never carry authority — otherwise prompt injection and "authority confusion" turn demos into production risks. It argues agents differ from chatbots because they act, so they need scoped tools, approval gates for high-impact actions, and full audit logging. The takeaway: a production-grade agent isn't just a prompt but a runtime system that must be constrained by architecture.

- 0
- 9
- 3 min read
capacity building
training
AI Governance and Board-Level Risk Oversight in the Age of Autonomous Enterprises: A Framework for Financial Resilience and Regulatory Accountability
AI Governance and Board-Level Risk Oversight in the Age of Autonomous Enterprises: A Framework for Financial Resilience and Regulatory Accountability
Manas Pandey
CEO, MS Risktec Solutions
Abstract
The rapid integration of Artificial Intelligence (AI) into enterprise decision-making has fundamentally transformed corporate governance, financial risk management, and regulatory accountability. Boards and executive leadership teams are increasingly required to supervise AI-driven systems that influence lending decisions, fraud monitoring, customer profiling, algorithmic trading, operational resilience, and strategic planning. However, traditional governance frameworks were not designed to address autonomous, continuously learning systems capable of creating systemic risks at unprecedented scale and speed. This paper examines the emerging role of board-level AI governance in strengthening enterprise resilience and proposes a structured governance model integrating Enterprise Risk Management (ERM), AI governance, cybersecurity oversight, and regulatory compliance.
The paper argues that AI risk can no longer be treated as a purely technological issue and must instead be embedded within corporate governance structures, audit mechanisms, and strategic decision-making processes. Drawing from evolving global regulatory frameworks—including the European Union AI Act[4], the Digital Personal Data Protection Act (India)[8], Basel operational risk principles[5], and ESG governance expectations—the paper introduces an integrated governance framework called Autonomous Intelligence Management Systems (AIMS). The framework emphasises explainability, accountability, fairness, resilience, and continuous monitoring of AI systems. The study concludes that organisations adopting board-driven AI governance structures are likely to achieve superior risk-adjusted performance, regulatory preparedness, and stakeholder trust.

- 0
- 30
- 1 min read
AI in Law
Constitutional Law AI
Law
Machine Learning in Law
Predictive Analytics in Law
Public Awareness
Public Law AI
Urban Development
Evidentiary Value of AI Generated Leads: A Critical Analysis of Navigating the Gap between Predictive Policing and Judicial Standards in India
"Evidentiary Value of AI-Generated Leads: A Critical Analysis of Navigating the Gap between Predictive Policing and Judicial Standards in India" explores the complex intersection of modern law enforcement technology and traditional legal frameworks.
As Indian law enforcement agencies increasingly adopt predictive policing tools to anticipate crime hotspots and identify suspects, a critical legal challenge emerges: determining the admissibility, reliability and weight of AI-generated leads in a court of law. This analysis delves into the inherent tension between the fast paced, probabilistic nature of algorithmic outputs and the rigorous, concrete evidentiary standards required by Indian jurisprudence.
Key themes addressed include:
1. The Black Box Dilemma: Examining how the lack of transparency in proprietary AI algorithms complicates traditional cross examination and challenges the fundamental right to a fair trial.
2. Constitutional Concerns: Assessing the impact of AI-driven policing on civil liberties, particularly concerning the Right to Privacy, data protection and potential algorithmic bias that could disproportionately target marginalized communities.
3. Evidentiary Thresholds: Analyzing how AI leads fit into existing Indian evidentiary laws (such as the Bharatiya Sakshya Adhiniyam) and the procedural safeguards required to transition an algorithmic prediction into legally admissible evidence.
This analysis seeks to bridge the widening gap between technological innovation in law enforcement and strict judicial safeguards. It aims to propose frameworks that ensure AI serves as an effective investigative aid while strictly upholding the principles of transparency, accountability and justice in India.

- 1
- 22
- 1 min read
Showing
Select Option
12
of 34 items
© 2026 - Copyright AIKosh. All rights reserved.